
I learned of a neat result due to Kevin Ventullo that uses group actions to study the structure of hash functions for unordered sets and multisets. This piqued my interest because a while back a colleague asked me if I could think of any applications of “pure” group theory to practical computer programming that were not cryptographic in nature. He meant, not including rings, fields, or vector spaces whose definitions happen to be groups when you forget the extra structure. I couldn’t think of any at the time, and years later Kevin has provided me with a tidy example. I took the liberty of rephrasing his argument to be a bit simpler (I hope), but I encourage you to read Kevin’s post to see the reasoning in its original form.
Hashes are useful in programming, and occasionally one wants to hash an unordered set or multiset in such a way that the hash does not depend on the order the elements were added to the set. Since collection types are usually generic, one often has to craft a hash function for a set<T> or multiset<T> that relies on a hash function hash(t) of an unknown type T. To make things more efficient, rather than requiring one to iterate over the entire set each time a hash is computed, one might seek out a hash function that can be incrementally updated as new elements are added, and provably does not depend on the order of insertion.
For example, having a starting hash of zero, and adding hashes of elements as they are added (modulo 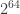
For example, if you adopt the XOR strategy for a multiset hash, then any element that has an even quantity in the multiset will be the same as if it were not in the set at all (or if it were in the set with some other even quantity). This is because x XOR x == 0. On the other hand, if you use the addition approach, if an element hashes to zero, its inclusion in any set has no effect on the hash. In Java the integer hash is the identity, so zero would be undetectable as a member of a multiset of ints in any quantity. Less drastically, a multiset with all even counts of elements will always hash to a multiple of 2, and this makes it easier to find hash collisions.
A natural question arises: given the constraint that the hash function is accumulative and commutative, can we avoid such degenerate situations? In principle the answer should obviously be no, just by counting. I.e., the set of all unordered sets of 64-bit integers has size 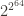
More than just “no,” we can characterize the structure of such hash functions. They impose an abelian group structure on the set of hashes. And due to the classification theorem of finite abelian groups, up to isomorphism (and for 64-bit hashes) that structure consists of addition on blocks of bits with various power-of-2 moduli, and the blocks are XOR’ed together at the end.
To give more detail, we need to review some group theory, write down the formal properties of an accumulative hash function, and prove the structure theorem.
Group actions, a reminder
This post will assume basic familiarity with group theory as covered previously on this blog. Basically, this introductory post defining groups and actions, and this followup post describing the classification theorem for commutative (abelian) groups. But I will quickly review group actions since they take center stage today.
A group 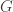
So a group action is formally a triple of a group 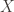
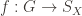
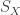
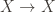
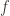
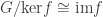
This relates to our hashing topic because an accumulative hash—and a nicely behaved hash, as we’ll make formal shortly—creates a group action on the set of possible hash values. The image of that group action is the “group structure” imposed by the hash function, and the accumulation function defines the group operation in that setting.
Multisets as a group, and nice hash functions
An appropriate generalization of multisets whose elements come from a base set 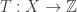
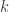
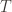
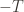
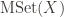
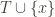

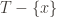
- An arbitrary base hash function
.
- An arbitrary hash accumulator
- A seed, i.e., a choice for the hash of the empty multiset
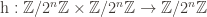
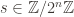
With these three data we want to define a multiset hash function 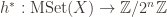
In order for the second bullet to lead to a well-defined hash, we need the property that the accumulation order of individual elements does not matter. Call a hash accumulator commutative if, for all 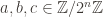
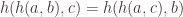
This extends naturally to being able to reorder any sequence of hashes being accumulated.
The third is a bit more complicated. We need to be able to use the accumulator to “de-accumulate” the hash of an element
Call a hash accumulator invertible if for a fixed hash 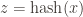
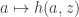

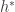
- Fix
be the inverse of the map
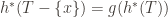
Though we don’t have a specific definition for the inverse above, we don’t need it because we’re just aiming to characterize the structure of this soon-to-emerge group action. Though, in all likelihood, if you implement a hash for a multiset, it should support incremental hash updates when removing elements, and that formula would apply here.
This gives us the well-definition of 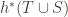
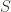
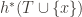
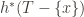
A group action emerges
Now we have a well-defined hash function on a free abelian group.
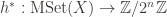
However, 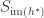
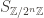
The group action is defined formally as a homomorphism

where 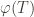
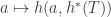

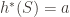
The map 
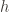
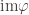
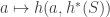
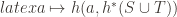
And now we can apply the first isomorphism theorem, that
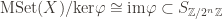
This is significant because any quotient of an abelian group is abelian, and this quotient is finite because
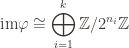
where 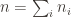
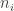
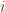
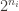
For example, the group might be 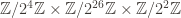
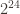
In one extreme case, you only have one block, and your group is just 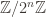
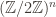
Note, if instead of 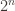
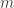
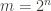
Implications for hash function designers
Here’s the takeaway.
First, if you’re trying to design a hash function that avoids the degeneracies mentioned at the beginning of this article, then it will have to break one of the properties listed. This could happen, say, by maintaining additional state.
Second, if you’re resigned to use a commutative, invertible, accumulative hash, then you might as well make this forced structure explicit, and just pick the block structure you want to use in advance. Since no clever bit shifting will allow you to outrun this theorem, you might as well make it simple.
Until next time!




![Erratum for “An inverse theorem for the Gowers U^s+1[N]-norm”](https://azmath.info/wp-content/uploads/2024/07/2211-erratum-for-an-inverse-theorem-for-the-gowers-us1n-norm-150x150.jpg)

